Getting Started
DataFu Spark Docs
DataFu Pig Docs
DataFu Hourglass Docs
Community
Apache Software Foundation
Apache DataFu Hourglass
Concepts
Apache DataFu Hourglass is designed to make computations over sliding windows more efficient. For these types of computations, the input data is partitioned in some way, usually according to time, and the range of input data to process is adjusted as new data arrives. Hourglass works with input data that is partitioned by day, as this is a common scheme for partitioning temporal data.
We have found that two types of sliding window computations are extremely common in practice:
- Fixed-length: the length of the window is set to some constant number of days and the entire window moves forward as new data becomes available. Example: a daily report summarizing the the number of visitors to a site from the past 30 days.
- Fixed-start: the beginning of the window stays constant, but the end slides forward as new input data becomes available. Example: a daily report summarizing all visitors to a site since the site launched.
We designed Hourglass with these two use cases in mind. Our goal was to design building blocks that could efficiently solve these problems while maintaining a programming model familiar to developers of MapReduce jobs.
The two major building blocks of incremental processing with Hourglass are a pair of Hadoop jobs:
- Partition-preserving: consumes partitioned input data and produces partitioned output.
- Partition-collapsing: consumes partitioned input data and merges it to produce a single output.
We'll discuss these two jobs in the next two sections.
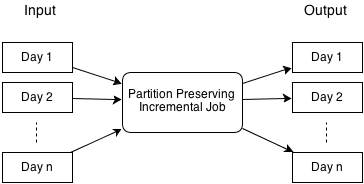
Partition-preserving job
In the partition-preserving job, input data that is partitioned by day is consumed and output data is produced that is also partitioned by day. This is equivalent to running one MapReduce job separately for each day of input data. Suppose that the input data is a page view event and the goal is to count the number of page views by member. This job would produce the page view counts per member, partitioned by day.
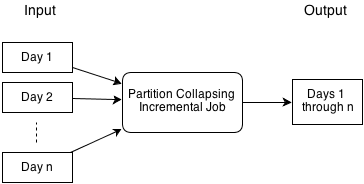
Partition-collapsing job
In the partition-collapsing job, input data that is partitioned by day is consumed and a single output is produced. If the input data is a page view event and the goal is to count the number of page views by member, then this job would produce the page view counts per member over the entire n days.
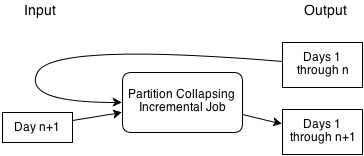
Functionally, the partition-collapsing job is not too different from a standard MapReduce job. However, one very useful feature it has is the ability to reuse its previous output, enabling it to avoid reprocessing input data. So if day n+1 arrives, it can merge it with the previous output, without having to reprocess days 1 through n. For many aggregation problems, this makes the computation much more efficient.
Hourglass programming model
The Hourglass jobs are implemented as MapReduce jobs for Hadoop:
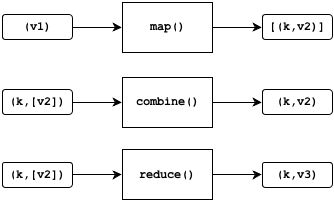
The map method receives values from the input data and, for each input, produces zero or more key-value pairs as output. Implementing the map operation is similar to implementing the same for Hadoop, just with a different interface. For the partition-preserving job, Hourglass automatically keeps the data partitioned by day, so the developer can focus purely on the application logic.
The reduce method receives each key and a list of values. For each key, it produces the same key and a single new value. In some cases, it could produce no output at all for a particular key. In a standard reduce implementation in Hadoop, the programmer is provided an interface to the list of values and is responsible for pulling each value from it. With an accumulator, this is reversed: the values are passed in one at a time and at most one value can be produced as output.
The combine method is optional and can be used as an optimization. Its purpose is to reduce the amount of data that is passed to the reducer, limiting I/O costs. Like the reducer, it also uses an accumulator. For each key, it produces the same key and a single new value, where the input and output values have the same type.
Hourglass uses Avro for all of the input and output data types in the diagram above, namely k, v, v2, and v3. One of the tasks when programming with Hourglass is to define the schemas for these types. The exception is the input schema, which is implicitly determined by the jobs when the input is inspected.

Apache DataFu, DataFu, Apache Pig, Apache Hadoop, Hadoop, Apache, and the Apache feather logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and other countries.